Base32 encoding
Categories: binary encoding data formats
Base32 encoding is similar to Base64 encoding, except that it uses an alphabet of 32 characters rather than 64. This alphabet consists of the characters A to Z, and numbers 2 to 7. The encoding is case insensitive – although an encoder should always produce uppercase output, a decoder can accept either case as input.
A version of the algorithm is described in RFC 3548.
Algorithm
Base32 encodes the input data five bytes at a time. Each block of five input bytes is encoded to create a block of eight printable characters.
The five bytes are ordered into a 40-bit value, starting from the most significant bit of Byte0, and ending with the least significant bit of Byte4. The bits are then arranged as a set of eight 5-bit numbers, N0 to N7. The first 5 bits form N0, the next 5 form N1 etc. Each 5-bit number has a range of 0 to 31.
The second stage is to convert numbers N0…N7 into ASCII characters, C0…C7. This is done according to the following table:
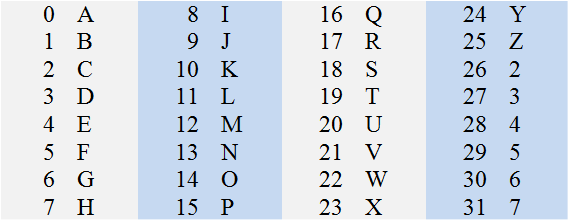
As with the hex encoder, it is probably wise to include a CRLF character pair inserted after every 80 characters (or less) of encoded data. Some implementations require this, most can cope with it even if they don’t require it.
The original data can be any length, not necessarily a multiple of 5. This means that the last block of binary data could be 1, 2, 3, 4 or 5 bytes long. To code the final block, we add zeros to the final block to make it a multiple of 5 and convert it to 5 characters as usual. However, we indicate the length of the block in the following way:
- If the final block has a length of 1 byte, the encoded characters consist of N0, N1, followed by 6 = characters (N2 to N7 contain no useful information anyway).
- If the final block has a length of 2 bytes, the encoded characters consist of N0, N1, N2, and N3, followed by 4 = characters.
- If the final block has a length of 3 bytes, the encoded characters consist of N0, N1, N2, N3, and N4, followed by 3 = characters.
- If the final block has a length of 4 bytes, the encoded characters consist of N0, N1, N2, N3, N4, N5, and N6, followed by a single = character.
If the final block has a length of 5 bytes, the encoded characters consist of N0 to N7 in the normal way.
Error Conditions
A decoder might encounter data which does not completely conform to the specification above. It is then up to the decoder to decide whether to ignore the discrepancy or indicate an error. Here are some of the main error cases:
Whitespace characters - if the data contains spaces, line breaks and other whitespace characters, it is probably safe to ignore them and decode the data as if they were not there. On the other hand, a decoder should not rely on the data having line feeds, because it might not always be the case.
Lowercase characters - Base32 data might contain characters a-z instead of A-Z. A decoder should accept this data, and treat upper and lower case characters as identical. (Of course, the encoder should always use upper case).
Illegal characters - any characters, other than CRLF, which are not part of the Base32 alphabet (ignoring case), probably indicate data corruption. There could be an argument for making a special case for space and tab characters
Incomplete last data block - if the data stream does not terminate correctly, then the data might have been truncated or otherwise corrupted.
See also
Sign up to the Creative Coding Newletter
Join my newsletter to receive occasional emails when new content is added, using the form below:
Popular tags
555 timer abstract data type abstraction addition algorithm and gate array ascii ascii85 base32 base64 battery binary binary encoding binary search bit block cipher block padding byte canvas colour coming soon computer music condition cryptographic attacks cryptography decomposition decryption deduplication dictionary attack encryption file server flash memory hard drive hashing hexadecimal hmac html image insertion sort ip address key derivation lamp linear search list mac mac address mesh network message authentication code music nand gate network storage none nor gate not gate op-amp or gate pixel private key python quantisation queue raid ram relational operator resources rgb rom search sort sound synthesis ssd star network supercollider svg switch symmetric encryption truth table turtle graphics yenc